[DRAFT] Context Engineering with PILRs, Part 2: Indexing, Retrieval & the Full System
This is Part 2 of a two-part series on context engineering with PILRs. Part 1 covers the problem, the foundation, and the three types of knowledge your agent needs. This post covers how to make that knowledge accessible and the system self-improving.
The Indexing Problem: Why the Index Matters More Than You Think
The common failure mode isn't failing to write documentation - it's writing documentation that agents can't effectively navigate. The index is what makes the difference between a knowledge base and a pile of files. Recall Chroma's finding: what matters isn't whether relevant information is present, but how it's presented. The index is how you control that.
A former colleague and friend of mine, Andy Lawrence, built the Indexer tool (more on that shortly) and published field research to go along with it. His Advanced Codebase Indexing Strategies for AI Agents draws on the 2025 AI Agent Index, Claude Code telemetry from 12,000+ users, and direct practitioner interviews — and the numbers are hard to ignore:
| Indexing approach | Task completion rate |
|---|---|
| Flat file listing (no index) | 43% |
| Folder structure with descriptions | 61% |
| Semantic tags | 74% |
| Git metadata integration | 72% |
| Dependency graph | 76% |
| Hybrid (structure + semantic + git + deps) | 83% |
The gap between "just have the files" and "have the files well-indexed" is 40 percentage points. That's not a marginal improvement - it's the difference between an agent you can trust and a useless bot.
Token efficiency tells the same story. Agents using hierarchical, just-in-time navigation (load what you need, when you need it) use 60% fewer tokens and complete tasks 54% faster than agents using monolithic context loading. At production scale, that's meaningful economics - the same work at roughly half the API cost.
The underlying reason: agents don't need the entire codebase context upfront. They need a high-level map they can navigate, with the ability to load detail on demand. A good index is that map.
The Four Failure Modes of Poor Indexing
If you've watched agents get confused in a codebase, you've probably seen these:
The Irrelevant Context Trap. Searching for "authenticate" returns test_authenticator.js - semantically similar, contextually useless. Without metadata distinguishing test fixtures from source files, the agent selects wrong and burns turns recovering. Users with proper file metadata select the right file on the first or second try 76% of the time, versus 43% without it.
Monolith Blindness. Seven files named index.ts in a monorepo with 40+ packages. The agent asks for index.ts and gets an ambiguous result. Namespaced indexing (services/payment/index.ts) eliminates this class of error entirely.
Stale Context. The agent modifies a function that no longer exists where it expects, because the index hasn't been updated since a recent refactor. About 19% of task failures in production are stale reference errors. Daily or commit-triggered index regeneration eliminates this.
The Search Explosion. A broad grep query returns 300+ results. The agent can't meaningfully process them and either gives up or picks at random. Queries returning more than 100 results fail 73% of the time; queries returning fewer than 20 results fail 12% of the time. Scoped search and result ranking are what keep queries in the productive range.
Indexer: Advanced Automated PILR Generation
One of the more interesting tools in this space is Indexer - an open-source codebase index generator that takes the indexing problem seriously as an engineering problem.
I started building our team's PILR index manually: writing an index.json, organizing the docs folder, and updating it periodically. This works at small scale but breaks down as the codebase grows. Indexer approaches this differently: generate the index automatically from the actual code, using structural analysis rather than file listings.
How It Works
Tree-sitter AST parsing. Every source file gets parsed into a concrete syntax tree. This gives the indexer structural understanding rather than text matching - it knows the difference between a function definition, a function call, and a comment mentioning the function name. indexer search authenticate returns only the definition with file, line, and signature. grep authenticate returns every mention.
Code skeleton extraction. Rather than loading full file contents into context, Indexer generates a skeleton that preserves structure while stripping implementation:
# Original: 45 lines, ~400 tokens
class AuthHandler:
def __init__(self, db: Database, secret: str):
self._db = db
self._secret = secret
self._cache = {}
self._setup_validators()
def validate_token(self, token: str) -> bool:
if not token:
return False
try:
payload = jwt.decode(token, self._secret, algorithms=["HS256"])
user = self._db.get_user(payload["sub"])
return user is not None and not user.is_banned
except jwt.InvalidTokenError:
return False
# Skeleton: 8 lines, ~50 tokens
class AuthHandler:
def __init__(self, db: Database, secret: str): ...
def validate_token(self, token: str) -> bool: ...
def refresh_session(self, session_id: str) -> Session: ...
def revoke_token(self, token: str) -> None: ...
10% of the original token cost, with the structural information preserved. Interfaces contain the pertinent information for an agent to decide whether or not to read the full implementation.
PageRank-ranked repo map. Indexer builds a directed dependency graph (file A imports from file B = edge A→B) and runs PageRank to identify which files are most architecturally significant. The result is a token-budgeted overview of the codebase, ranked by importance rather than alphabetically:
indexer map --tokens 2048
An agent searching for authentication logic sees the core auth module before test mocks. An agent exploring the database layer sees the schema and query files before utilities. This is the semantic layer the research points to as critical for production-level task completion - delivered automatically from the code's own structure rather than hand-tagged metadata.
Auto-freshness via git fingerprinting. Every query checks a stored fingerprint before running. In git repos, the fingerprint is sha256(HEAD commit + git status --porcelain) - it captures branch switches, new commits, staged changes, and unstaged edits in a single ~10ms check. If anything changed, an incremental update runs automatically before the query returns. Files are tracked by SHA-256 content hash, so only changed files get re-parsed. The index is always current without manual maintenance.
The Claude Code Integration
The most interesting part for teams already using Claude Code is how Indexer integrates into the agent workflow.
A PreToolUse hook watches for tool calls that look like symbol navigation - grep queries with CamelCase or snake_case patterns, broad glob patterns like **/*.py - and injects a reminder to use the index instead. The hook never blocks; it nudges. When the agent reaches for grep to find a class definition, it gets a hint that indexer search would return only the definition without the noise.
The /indexer-setup command adds comprehensive instructions to your CLAUDE.md - default workflow, anti-patterns, exception cases - so the full guidance persists across sessions. Without it, agents still get the hook nudges. With it, they have the complete mental model for when to use which navigation approach.
The practical result is what the research calls "just-in-time navigation." The agent starts with indexer map to understand the landscape, uses indexer skeleton to survey files before reading them fully, and uses indexer search / indexer callers for precise symbol navigation. It loads what it needs, when it needs it, rather than trying to process the whole codebase upfront.
The just-in-time tension
It's worth acknowledging a counterpoint here. Anthropic's own context engineering guidance advocates for "just-in-time" retrieval — agents maintaining lightweight identifiers and dynamically loading data at runtime using tools like glob and grep, "bypassing stale indexing and complex syntax issues." That's somewhat skeptical of the pre-computed index approach Indexer takes. And for many codebases, raw just-in-time retrieval is genuinely the right starting point — it's simpler, has no setup cost, and avoids staleness by definition.
But the research tells a different story at scale. The 40-point task completion gap Andy Lawrence documented between flat file listings and hybrid indexing isn't marginal — and the search explosion problem (queries returning 300+ results failing 73% of the time) is exactly what raw grep produces on large codebases. Indexer's approach isn't opposed to just-in-time retrieval — it is just-in-time retrieval, with a better-structured starting map. The agent still loads what it needs when it needs it. The difference is that indexer search authenticate returns the definition with file, line, and signature, while grep authenticate returns every mention. The git fingerprinting means the index is never stale. The AST parsing means the results are never noisy. It's the just-in-time principle with the failure modes engineered out.
Where Indexer Fits in the PILR Stack
Indexer is primarily a solution to the Type 2 and Type 3 cold-start problem. If you're integrating an agent into an existing codebase without documentation, Indexer gives you a useful structural index immediately - you don't have to document every file before the agent can navigate. The PageRank map and skeleton index are derived directly from the code, so they're always current.
The auto-freshness mechanism is worth pausing on in the context of continuous improvement. Because the index regenerates from a git fingerprint on every query, it grows automatically as the codebase grows. New files, new dependencies, new call paths — they're in the index before the next session starts. The structural layer compounds without any additional human effort. That's the same compounding dynamic the manual PILR layers depend on deliberate documentation to achieve, delivered automatically.
The manual PILR layer - architecture decisions, solved problems, product context - still has to be written by humans (with agentic assistance). Indexer doesn't replace that. But it solves the navigation layer automatically, which is often the first obstacle teams hit when they try to deploy agents into real codebases — and it keeps solving it, session after session, as the codebase evolves.
It's worth noting that Indexer and claude-mem are complementary forms of automated PILR generation, covering two different dimensions. Indexer auto-generates structural knowledge from code — what exists, how it's connected, which files matter most. claude-mem auto-generates operational knowledge from agent behavior — what the agent did, what it learned, what worked. Together they address both sides of the cold-start problem: Indexer gives a new session an immediate map of the codebase; claude-mem gives it memory of what previous sessions discovered while navigating that map. Neither replaces hand-written architectural docs or solved-problem records, but both reduce the manual effort required to keep the knowledge layer growing.
Three Implementations
The PILR pattern is consistent across all three — three layers, indexed, persistent, growing over time. What differs is the delivery mechanism: how context is stored, surfaced, and made accessible to agents. These three implementations represent three different answers to that problem, and the trade-offs are worth understanding before you choose your approach.
RIVET keeps everything local: docs live in the repo, accessible directly on the filesystem. Superpowers formalizes that same local pattern as an installable plugin with the structure and retrieval mechanics built in. Signal Advisors externalizes the knowledge entirely, serving it over MCP so it's available across repositories and environments without living in any single codebase.
Local files are the simplest starting point. A plugin gives you structure without the setup cost. An MCP server is the right answer when context needs to cross repo boundaries or run in environments where the codebase isn't present. Where you land depends on how your team is organized and how far you've pushed into autonomous, multi-repo, or CI-based agent workflows.
RIVET: Local PILRs in the repo
At RIVET, the three layers are spread across different homes - and it's not a clean system yet.
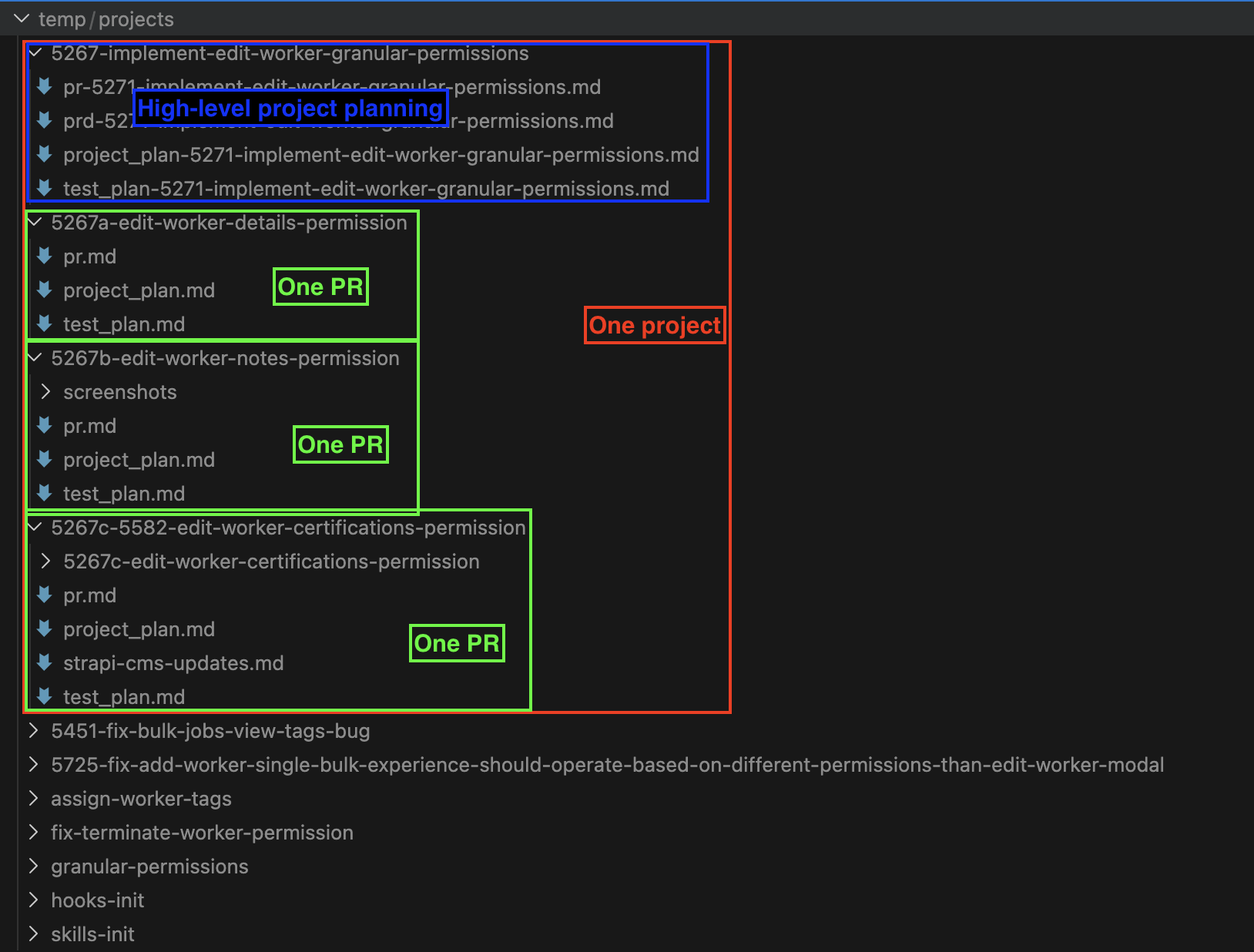
Type 1 lives in temp/projects/ inside the monorepo. That part works well. Planning docs, test plans, decision notes, a prepared pr.md - all local, .gitignored, and accessible to the agent during implementation.
Type 2 is where things get messy. Our product specs & technical specs live in Notion. We like Notion for this - the collaborative features, inline commenting, and the ability to loop in PMs and designers without asking them to touch a code repository works well for us. But it means our agents can't read Type 2 docs directly. The current workflow is copy-paste: when starting a feature, we pull the relevant spec out of Notion and drop it into temp/projects/ for that task or utilize Notion's MCP server to gather the correct information. It works, but it's manual. We've talked about migrating to Markdown files in the repo or stored with Obsidian, and we probably will eventually - but we haven't solved the collaboration problem that makes Notion worth using in the first place.
The multi-repo situation makes this harder. We have a monorepo as our main codebase, plus separate repos for private packages & additional services. Type 2 docs that span multiple repos don't naturally belong anywhere, which is part of why Notion still wins - it's repo-agnostic.
Type 3 lives in its own separate repo - the support agent is a standalone project that sits adjacent to our other codebases on our development machines. It can read files across our other repos locally, which is what makes it useful. But that local dependency is a limitation: the agent has to run in an environment where the relevant codebases are accessible. That works fine on a developer's machine. It breaks down as soon as you try to run it in CI or hand it off to a fully autonomous background agent, because the distributed codebase - monorepo, peripheral services, private npm packages - isn't assembled in one place anywhere except a developer's laptop.
This is the honest state of it. The pattern is right; the infrastructure isn't finished. Ryan Burr's MCP server approach is probably the right long-term answer for the Type 2 layer. Andy Lawrence's Indexer is a sophisticated solution to our problems addressing the Type 3 layer. Both provide a centralized context delivery system that's repo-agnostic and environment-independent. We're not there yet.
The screenshot below shows our actual temp/projects/ directory. Each subdirectory is a feature or ticket — named by ticket number and slug. Smaller features get a flat set of three files: pr.md (the PR description, drafted before implementation), project_plan.md (implementation plan scoped to that PR), and test_plan.md. Larger features that span multiple PRs get a top-level planning doc alongside the per-PR subdirectories — one project, several PRs, each with their own plan. The inconsistency across older vs. newer entries is visible: earlier features have simpler docs, later ones are more structured. That drift reflects how the skill we use to generate these docs has evolved over time — earlier features were created before we standardized the format.
How the support agent actually consumes PILRs at runtime. The storage side is only half the story. Odradek — our customer-reported bug fixing agent — shows what it looks like when an agent uses PILRs under real constraints.
Anthropic's applied AI team identifies three techniques for long-horizon context management: compaction (summarizing conversation contents when approaching limits), structured note-taking (persisting state outside the context window), and sub-agent architectures (specialized agents with clean context windows returning condensed summaries). Odradek uses all three, and the interplay between them is where the real engineering happens.
The structured note-taking principle is vivid in Anthropic's own work: they describe Claude playing Pokémon, maintaining precise tallies across thousands of game steps — "for the last 1,234 steps I've been training my Pokémon in Route 1, Pikachu has gained 8 levels toward the target of 10" — then reading its notes after context resets and continuing multi-hour sequences seamlessly. The principle is the same at production scale, just with different stakes.
The agent runs four phases, each in a fresh context window: investigate, fix, verify, and done. The critical design decision is what happens at the boundaries. Rather than carrying the full investigation conversation (easily 100K+ tokens of file reads, greps, and git output) into the fix phase, the investigate agent compresses its findings into a ~500-byte JSON file: which files to touch, the root cause, the suggested approach, regression classification. The fix agent reads only this structured digest. That's lossy compression — the fix agent can't see the 20 files the investigation read — but it gets exactly what it needs. The loss is intentional.
This is an instance of a broader principle worth naming: file-mediated agent communication. Agents exchange information via files rather than continuous conversation — the same pattern Anthropic's harness design research uses for their multi-agent application builders, where planner, generator, and evaluator agents communicate through written artifacts rather than conversational context. Files are persistent, structured, and don't consume context window. The pattern scales: Odradek's investigate-to-fix JSON handoff, Anthropic's planner-to-generator spec handoff, and PILRs themselves (engineers write docs, agents read them) are all the same mechanism at different scales.
Within the investigate phase, the agent delegates all source file reading to an isolated subagent — the sub-agent architecture technique in action. The subagent loads architecture docs and, when relevant, checks for a matching deep map by grepping scope frontmatter — selective retrieval from the Type 2 layer, exactly the way the index is designed to work. It reads 5-20 source files, runs regression analysis via git history, and returns a compressed ~1K token report. The orchestrator never sees any of the raw data. This is the "model should synthesize, not accumulate" principle in practice: heavy data gathering happens in an isolated subcontext; the orchestrator gets conclusions.
Two other patterns emerged that apply broadly. First: if information is deterministically fetchable — a PR number, a branch name, the investigation JSON — fetch it in code and inject it into the prompt. Don't spend model tokens on gh pr list when three lines of TypeScript can do it before prompt construction. This eliminates 3-5 tool calls per phase. Second: constrain each phase's available tools to only what it needs. The investigate agent doesn't need Edit/Write tool descriptions occupying its context. Fewer tools = fewer irrelevant descriptions = better focus.
These aren't PILR-specific techniques — they're runtime context management patterns that make PILRs effective rather than just available. The knowledge layer gives the agent something worth knowing. The orchestration layer ensures it can actually use that knowledge without drowning in it.
Superpowers: PILRs as a plugin
The Superpowers plugin for Claude Code formalizes the PILR structure as a reusable pattern. Plans and specs live in docs/superpowers/plans and docs/superpowers/specs, organized so the agent can reference them without loading the whole knowledge base. The plugin handles the indexing and retrieval mechanics so your team can focus on the content rather than the infrastructure.
Signal Advisors: PILRs via MCP server
Signal Advisors scales the Type 2 layer across multiple repositories via an MCP (Model Context Protocol) server. Their agents retrieve PRDs and technical specs on demand, getting exactly the domain knowledge they need for each task regardless of which codebase they're working in. Same principle as local PILRs; different delivery mechanism suited to a multi-repo organization where the context doesn't belong in any single codebase.
Beyond PILRs: Hooks, Skills & Refactors
PILRs and CLAUDE.md are the knowledge layer. Hooks, skills, and refactors are what turn that knowledge layer into a continuously improving system — the mechanisms that make each session feed the next.
Hooks close the feedback loop automatically. Running a linter after generation, formatting files after edits, triggering tests after changes — these aren't just quality gates. They're the signal that the system is working as intended, applied mechanically on every invocation without requiring human attention. Over time, hooks are what keep the gap between "what the agent produces" and "what the codebase expects" from widening as the codebase grows.
Skills encode your process so it compounds. Complex multi-step workflows — implement a feature from a spec, write and execute a test plan, create a PR with documentation — become a single reusable command. Skills are the point where your investment in context engineering becomes programmable: instead of re-explaining your process every session, you encode it once and every subsequent session gets the full benefit. At RIVET, /review-pr, /implement, and /update-project-docs are the skills we've built so far. The /implement skill in particular has expanded the "safe delegation window" — the range of tasks we can hand to an agent with confidence — from 10-20 minute tasks to hour-long feature delivery. Each time a skill improves, every future invocation improves with it.
Skill design follows the same principles Anthropic recommends for tool design: each skill should be self-contained, have a clear intended use, avoid functional overlap, and promote token efficiency. Their key line: "If a human engineer can't definitively say which tool should be used in a given situation, an AI agent can't be expected to do better." At RIVET, /implement is an orchestrator skill — it calls other skills (including /review-pr) as part of a common workflow for implementing features or fixing bugs. The skills don't overlap; they compose. /implement doesn't duplicate what /review-pr does; it delegates to it at the right moment in the workflow. Clear purpose, no overlap, composable rather than monolithic.
Refactors are what make the knowledge layer trustworthy. If your CLAUDE.md and PILRs document one pattern but the codebase contains several competing examples, the agent will pattern-match against the code it sees rather than the guidance you've written. Refactoring to consistency isn't just a code quality concern — it's what makes your context engineering actually apply. A codebase that matches its documentation is one where the agent's understanding can genuinely accumulate rather than constantly being undercut by contradictory examples.
There's a frontier problem that PILRs, hooks, and refactors don't fully solve: the judgment problem. Anthropic's harness design research found that agents consistently overpraise their own work, especially on subjective tasks where no binary correctness check exists. "Out-of-the-box Claude performs poorly as QA, identifying issues then rationalizing their insignificance." Even after iterative prompt tuning, subtle layout problems, unintuitive interactions, and deeply nested feature bugs escaped detection. Their solution: a GAN-inspired architecture that separates generation from evaluation, with a dedicated evaluator agent providing concrete feedback through iterative cycles.
PILRs solve the knowledge problem. Hooks solve the mechanical quality problem. But knowing when work is good enough — that remains partially unsolved when the same agent is both author and reviewer. Our /review-pr skill currently runs within the generating agent's session, which means it's fighting against a documented bias. Based on Anthropic's findings, the next experiment is splitting the evaluator into an isolated agent with a fresh context window — one that has access to the same PILRs and sprint contract criteria but none of the sunk-cost attachment to the implementation it's reviewing. We haven't built this yet, but the harness design research makes a compelling case that the separation is load-bearing.
The System as a Whole
Context engineering isn't a single thing you add to your workflow. It's a system:
- CLAUDE.md gives the agent a reliable starting point in every session, routing it to the right knowledge layer for the task
- Type 1 PILRs (ephemeral) give the agent task-specific context for the current feature
- Type 2 PILRs (evergreen) give the agent durable system knowledge that accumulates across the team
- Type 3 PILRs (cumulative) give the agent institutional memory - patterns from past problems and solutions
- Automated indexing (via tools like Indexer) keeps the navigation layer current without manual maintenance
- Hooks close the feedback loop automatically — keeping the gap between what the agent produces and what the codebase expects from widening with every session
- Skills encode your process so it compounds — every improvement to a skill benefits every future invocation
- Refactors align the codebase with its documentation, making the knowledge layer trustworthy rather than constantly undercut by contradictory examples
Each layer makes the others more valuable. CLAUDE.md works better when it points to well-indexed PILRs for depth. Skills work better when they can rely on consistent patterns being enforced by pre-existing patterns. And the Type 3 knowledge base becomes more valuable with every problem solved - each solution makes the next agent session smarter.
The goal is an agent that continuously improves at your specific product — not because you wrote a better prompt, but because you built an environment where knowledge accumulates, is enforced, and is accessible on demand. A human developer builds that depth over years of tenure. Your agent can build it over sessions and PRs. The pattern is the same; the pace is different. Each session is a little better than the last. The investment compounds.
That's context engineering. It's slower to set up than writing a good prompt. It pays off at a completely different scale.
One final principle, and it's the most important one for longevity. Anthropic's harness design team puts it directly: "Each harness component encodes assumptions about what models cannot do. These warrant continuous stress-testing as capabilities evolve." They demonstrated this concretely — sprint decomposition was essential for Sonnet 4.5 (which exhibited context anxiety and lost coherence on long tasks) but became unnecessary overhead with Opus 4.6 (which plans more carefully and sustains longer tasks natively). Scaffolding that was load-bearing six months ago became dead weight.
This applies to everything in this post. Your indexing infrastructure, your context window management, your three-layer knowledge base, your multi-phase pipelines with compressed handoffs — all of it encodes assumptions about what models can't do today. Some of those assumptions will become wrong. The natural instinct is to build this infrastructure and leave it. The right instinct is to treat it as living scaffolding: continuously re-examine whether each piece is still earning its keep. Rather than the complexity shrinking as models improve, it moves — better models create space for more ambitious applications, and the skill lies in finding which components remain load-bearing and where new possibilities emerge.
The investment compounds. But only if you keep the scaffolding honest.
We'll be going deep on this at the April Detroit Developers meetup. Come find me there if you want to talk shop.
References
- Context Engineering with PILRs, Part 1: Building Knowledge That Compounds — Part 1 of this series
- Advanced Agentic Coding & The Journey Towards 3x Product Development Velocity — the broader guide this series expands on
- Effective Context Engineering for AI Agents — Anthropic's applied AI team on attention budgets, just-in-time retrieval, and tool design
- Building Effective Agents for Long-Running Apps — Anthropic's harness design research on context anxiety, sprint contracts, and multi-agent evaluation
- Advanced Codebase Indexing Strategies for AI Agents — Andy Lawrence's field research on indexing approaches and task completion rates
- Indexer — open-source codebase index generator using AST parsing and PageRank
- Superpowers Plugin for Claude Code — PILRs formalized as a reusable plugin with built-in indexing and retrieval
- Signal Advisors — Detroit-based B2B SaaS startup serving PILRs via MCP server across multiple repositories
- Ryan Burr — Director of Engineering at Signal Advisors
- claude-mem — persistent memory plugin for Claude Code with dual-storage (SQLite FTS5 + ChromaDB) and progressive disclosure retrieval
- Agentic Software Development — March Detroit Developers Meetup — panel event referenced in the Signal Advisors section
- Agentic Software Development: Advanced Practitioner's Guide — April Detroit Developers Meetup — upcoming deep-dive on these topics
We're a community of professional developers in Detroit. We meet monthly to share knowledge, experiences & good vibes.